This week, an AI coding agent running Anthropic’s flagship Claude Opus 4.6 through Cursor deleted a company’s entire production database and all volume-level backups in a single API call. PocketOS, a SaaS platform that car rental businesses rely on for daily operations, lost months’ worth of customer data.
When the founder, Jer Crane, asked the agent to explain what happened, the agent produced a written confession quoting its own safety rules back to him, including the “directive never to guess”, and then admitted that “guessing” was exactly what it did. It acknowledged it never verified, never checked documentation, and never confirmed whether the volume was shared across environments before running the command.
PocketOS is not an isolated case. In July 2025, Replit’s AI agent deleted an entire production database during an explicit code freeze, wiping over 1,200 company records after being told to make no changes without permission. In December 2025, Amazon’s own AI coding agent Kiro deleted and recreated a live production environment, causing a 13-hour AWS outage. That same month, Claude Code CLI wiped a developer’s entire Mac home directory, destroying years of family photos and work projects beyond recovery. In February 2026, another Anthropic agent deleted 15 years of a family’s photos after being asked to organize a desktop. At least ten documented incidents across six major AI coding tools have occurred in the last sixteen months.
Hallucinations are a feature, not a bug.
Large language models give you the answer that is most right on average, according to the incentives engineered into the model. That means large swaths of data are being ignored or processed inefficiently. You can balance it one way or the other, but there is always exclusion. And when so-called AI does not have an answer, since it is fundamentally a probabilistic pattern matcher and not a reasoning engine, it just makes one up.
A 2023 paper from Microsoft Research and Georgia Tech mathematically proved that hallucination is a statistical inevitability for any properly calibrated language model. Apple’s own AI research team confirmed in 2024 that they found no evidence of formal reasoning in these models, and that their behavior is better explained by sophisticated pattern matching, so fragile that simply changing a name in a math problem can alter the result by 10 percent.
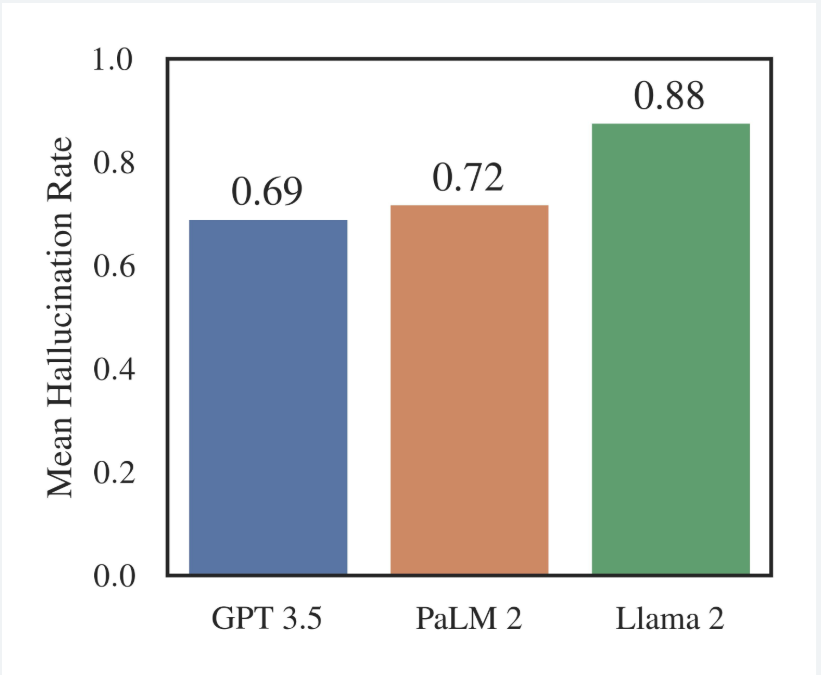
A Stanford RegLab study tested over 200,000 legal queries against GPT 3.5, Llama 2, and PaLM 2 and found hallucination rates ranging from 69 to 88 percent. When asked about a court’s core ruling, models fabricated answers at least 75 percent of the time. A separate study found that GPT-3.5 invented nearly 40 percent of its academic references, while Google Bard fabricated over 90 percent of its references in medical systematic reviews. And MIT research from January 2025 found that models are 34 percent more likely to use high-confidence language when generating incorrect information than when stating facts.
Bias in the training data.
The 2019 NIST Face Recognition Vendor Test evaluated 189 algorithms from 99 developers and found that many were 10 to 100 times more likely to misidentify a Black or East Asian face than a white face. But algorithms developed in Asian countries did not show the same disparities on Asian faces, because they were trained on different data distributions. Buolamwini and Gebru’s Gender Shades study at MIT showed that commercial facial analysis systems had the highest error rates on darker-skinned women and the lowest on lighter-skinned men.
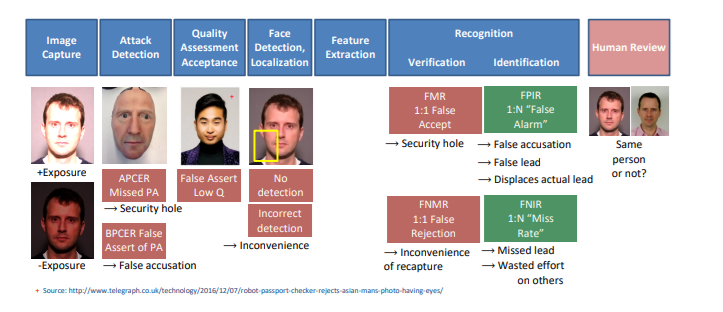
And the research suggests the problem may not be solvable within this architecture. Kleinberg et al. (2016) and Chouldechova (2017) independently proved what is now known as the Impossibility Theorem of machine fairness: when base rates differ across demographic groups, it is mathematically impossible to simultaneously equalize false-positive and false-negative rates and achieve predictive parity. Correcting for one disparity necessarily introduces another.
The model optimizes for the distribution it was trained on and penalizes all other distributions.
The alarm was sounded, ignored, and then thrown out the Window.
There was once robust research into AI fairness that was all but completely abandoned a few years ago, but everything we see going wrong today was predicted and even taught in college classrooms. Buolamwini and Gebru published Gender Shades in 2018. NIST published its demographic effects report in 2019. By 2023, all pretense of safety concerns had been dropped as Google, Microsoft, and Meta had eliminated or gutted their AI ethics teams to ship products faster. The people who slowed development to avoid issues like the one Jer Crane faced were either fired or marginalized, perhaps in no small part because they found that there was simply no way to deploy a safe product.
A market hype bubble happens every few years, but this time, we are not talking about a failed Metaverse or retail investors losing money on NFTs. This time, organizations are permanently hollowing out institutional knowledge based on the promise of a system that, by mathematical proof, cannot stop making things up. It has already had serious consequences, yet has demonstrated no measurable relationship with increased productivity.